

Beschrijvende statistiekengeschiedenis, kenmerken, voorbeelden, concepten

- 2573
- 44
- James Dach
De Beschrijvende statistieken Het is de tak van statistieken die zich bezighouden met het verzamelen en organiseren van informatie over het gedrag van systemen met veel elementen, algemeen bekend als de naam van bevolking.
Hiervoor gebruikt het numerieke en grafische technieken, waardoor het informatie presenteert, zonder voorspellingen of conclusies te doen over de bevolking waar het komt.
De beschrijvende statistieken worden geacht de informatie gemakkelijk te organiseren en te presenteren [TOC]
Geschiedenis
Oude leeftijd
Statistieken hebben zijn oorsprong in de menselijke behoefte om de nodige informatie te organiseren voor het voortbestaan en goeden, en om te voorzien in de gebeurtenissen die dit beïnvloeden. De grote beschavingen van de oudheid lieten gegevens over van kolonisten, geïndiceerde belastingen, hoeveelheid gewassen en de grootte van de legers.
Tijdens zijn lange bewind bijvoorbeeld, Ramses II (1279-1213 tot.C) bestelde een volkstelling van land en inwoners in Egypte, die toen ongeveer 2 miljoen inwoners had.
Evenzo heeft de Bijbel dat Mozes een volkstelling uitvoerde om te weten hoeveel soldaten de twaalf stammen van Israël hadden.
Ook werden in oude Griekenland tellingen van mensen en middelen gemaakt. De Romeinen, opmerkelijk voor hun hoge organisatie, registreerden de bevolking periodiek en bereidden om de vijf jaar tellingen, inclusief gebieden en middelen.
Renaissance
Na de achteruitgang van Rome waren de belangrijke statistische gegevens bang, tot de komst van de Renaissance, wanneer de statistieken opduiken.
De waarschijnlijkheidstheorie werd geboren, met als gevolg.
Moderne tijd
Een nieuwe impuls kwam met de theorie van fouten en de minimale vierkanten in de negentiende eeuw, die volgden op de methode van correlatie tussen variabelen, om de relatie tussen hen kwantitatief te beoordelen.
Tot uiteindelijk, tijdens de twintigste eeuw, strekten statistieken zich uit tot elke tak van wetenschap en engineering als een onmisbaar hulpmiddel bij het oplossen van problemen.
Kenmerken van beschrijvende statistieken
Beschrijvende statistieken worden gekenmerkt door:
- Organiseer informatie verzameld in gegevens en afbeeldingen. De grafieken kunnen divers zijn: histogrammen, frequentie polygonen, cake -vormige diagrammen, onder andere.
- Distribueer gegevens in frequentiebereiken om hun beheer te vergemakkelijken. Gebruik rekenkundige om de meest representatieve waarden van de gegevens te vinden, door middel van centrale neigingsmaatregelen, en analyseer de dispersie ervan.
- Bepaal de vorm van de distributies, hun symmetrie, als ze gecentreerd of bevooroordeeld zijn, en als ze worden gericht of liever afgeplat.
Kan u van dienst zijn: impliciete derivaten: hoe ze worden opgelost en opgeloste oefeningenWat is beschrijvende statistieken voor?
Wanneer het nodig is.
Dan noemen we enkele voorbeelden:
Economie
Beschrijvende statistieken gaan over het registreren en organiseren van gegevens over populaties en hun leeftijd, inkomsten, investeringen, winst en uitgaven. Op deze manier plannen overheden en instellingen verbeteringen en investeren ze op de juiste manier.
Met uw hulp kunt u aankopen, verkoop, rendement en dienstenefficiëntie controleren. Om deze reden zijn statistieken onmisbaar bij het nemen van beslissingen.
Fysica en mechanisch
Fysica en mechanica gebruiken statistieken voor de studie van continue media, die bestaan uit een groot aantal deeltjes, zoals atomen en moleculen. Het blijkt dat het niet mogelijk is om elk van hen afzonderlijk te controleren.
Maar het bestuderen van het globale gedrag van het systeem (bijvoorbeeld een gasgedeelte) vanuit het macroscopische oogpunt is het mogelijk om gemiddelden te achterhalen en macroscopische variabelen te definiëren om de eigenschappen te kennen. Een voorbeeld hiervan is de kinetische theorie van gassen.
Geneesmiddel
Het is een essentieel hulpmiddel bij het monitoren van ziekten, van zijn oorsprong en tijdens zijn evolutie, evenals de werkzaamheid van behandelingen.
De statistieken die de percentages van morbiditeit, genezing, incubatietijden of ontwikkeling van een ziekte, de leeftijd waarop deze meestal verschijnt, beschrijven, zijn nodig bij het ontwerpen van de meest effectieve behandelingen.
Voeding
Een van de vele toepassingen van beschrijvende statistieken is het registreren en bestellen van gegevens over de consumptie van voedsel in de verschillende populaties: hun kwantiteit, kwaliteit en die de meest geconsumeerde zijn, naast vele andere observaties die experts interesseren.
Voorbeelden van beschrijvende statistieken
Hieronder zullen we enkele voorbeelden zien die illustreren hoe nuttig de tools van beschrijvende statistieken zijn om beslissingen te nemen:
voorbeeld 1
 Om de eetkamers op school te verbeteren, is gebruikersinformatie vereist. Bron: Wikimedia Commons.
Om de eetkamers op school te verbeteren, is gebruikersinformatie vereist. Bron: Wikimedia Commons. De onderwijsautoriteiten van een landelijke planinstitutionele verbeteringen. Stel dat ze een nieuw systeem van school eetkamers zullen implementeren.
Hiervoor is het noodzakelijk om gegevens over de studentenpopulatie te hebben, bijvoorbeeld het aantal studenten per cijfer, hun leeftijd, geslacht, lengte, gewicht en sociaal -economische toestand. Dan wordt deze informatie gepresenteerd in de vorm van tabellen en grafieken.
Voorbeeld 2
Om het lokale voetbalteam te controleren en nieuwe signeersessies te maken, dragen managers het aantal gespeelde, gewonnen, gewonnen, verbonden en verloren, evenals het aantal doelpunten, scorers en hoe ze erin slaagden te scoren: vrije trap, van de halve rechtbank, penalty's, met linkerbeen of rechts, onder andere details.
Het kan u van dienst zijn: wederzijds exclusieve gebeurtenissen: eigenschappen en voorbeeldenVoorbeeld 3
Een ijssalon heeft verschillende smaken ijs en willen hun verkoop verbeteren, daarom voeren de eigenaren een onderzoek uit waarbij ze het aantal klanten tellen, ze in groepen scheiden per geslacht en leeftijdscategorieën.
In deze studie worden de favoriete ijsmaak en de best verkopende presentatie bijvoorbeeld opgenomen. En met de verzamelde gegevens plannen ze de aankopen van de smaken en de benodigde containers en accessoires voor hun voorbereiding.
Basisconcepten van beschrijvende statistieken
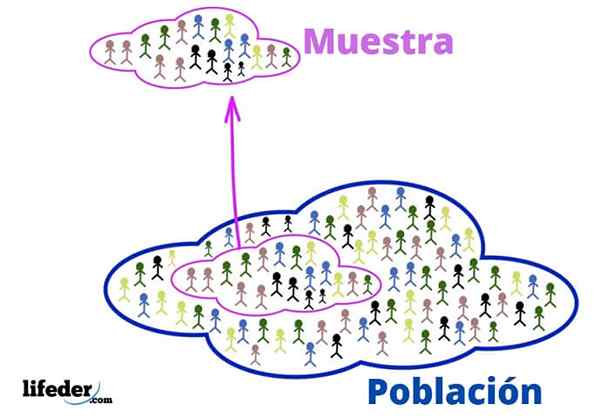 Bevolking en steekproef
Bevolking en steekproef Deze fundamentele concepten zijn nodig om statistische technieken toe te passen, laten we eens kijken:
Bevolking
In de statistische context verwijst de bevolking naar het universum of collectief waaruit de informatie komt.
Het gaat niet altijd om mensen, omdat het sets van dieren, planten of objecten zoals auto's, atomen, moleculen en zelfs gebeurtenissen en ideeën kunnen zijn.
Steekproef
Wanneer de populatie erg groot is, wordt er een representatieve steekproef uit geëxtraheerd en geanalyseerd, zonder relevante informatie te verliezen.
Het kan willekeurig worden gekozen, of volgens sommige criteria die eerder door de analist zijn vastgesteld. Het voordeel is dat het een subset van de bevolking is, het is veel beter beheersbaar.
Variabel
Het verwijst naar de reeks waarden die een bepaald kenmerk van de bevolking kunnen nemen. Een studie kan verschillende variabelen bevatten, zoals leeftijd, geslacht, gewicht, academisch niveau, civiele status, inkomen, temperatuur, kleur, tijd en nog veel meer.
De variabelen kunnen van verschillende aard zijn, dus er zijn criteria om ze te classificeren en ze de meest geschikte behandeling te geven.
Categorische variabelen en numerieke variabelen
Volgens de manier waarop ze worden gemeten, kunnen de variabelen zijn:
-Categorisch
-Numeriek
De categorische variabelen, ook wel genoemd kwalitatief, Ze vertegenwoordigen kwaliteiten zoals de civiele status van een persoon, die alleenstaand, getrouwd, gescheiden of weduwe kan zijn.
Aan de andere kant, naar numerieke variabelen of kwantitatief, Ze kunnen worden gemeten, zoals leeftijd, tijd, gewicht, inkomen en meer.
 De afbeeldingen zijn erg belangrijk om de informatie te presenteren, omdat in één oogopslag de gegevenstrend wordt gewaardeerd. Bron: PiqSels.
De afbeeldingen zijn erg belangrijk om de informatie te presenteren, omdat in één oogopslag de gegevenstrend wordt gewaardeerd. Bron: PiqSels. Discrete en continue variabele variabelen
Discrete variabelen nemen alleen discrete waarden aan, zoals de naam al aangeeft. Voorbeelden van hen zijn het aantal kinderen van een gezin, hoeveel onderwerpen zijn er in een bepaalde cursus en de hoeveelheid auto's op een parkeerplaats.
Deze variabelen nemen niet altijd hele waarden aan, omdat er ook breuken zijn.
Aan de andere kant laten continue variabelen oneindige waarden binnen een bepaald bereik toe, zoals het gewicht van een persoon, de pH van het bloed, de tijd van een telefoonconsult en de diameter van de voetbalballen.
Kan u van dienst zijn: symmetrieMaatregelen van centrale neiging
Geef een idee van de algemene trend dat de gegevens volgen. We zullen de drie meest gebruikte centrale maatregelen noemen:
-Half
-Mediaan
-Mode
Half
Gelijk aan de gemiddelde waarden. Het wordt berekend door alle waarnemingen toe te voegen en te verdelen tussen het totale aantal:

Mode
Het is de waarde die het meest wordt herhaald in een gegevensset, de meest voorkomende, omdat er in een verdeling meer dan één mode kan zijn.
Mediaan
Bij het bestellen van een gegevensset is de mediaan de centrale waarde van ze allemaal.
Dispersiemaatregelen
Ze wijzen op de variabiliteit van de gegevens en geven een idee van hoe ver of verspreid ze zijn van de centrale maatregelen. De meest gebruikte zijn:
Bereik
Het is het verschil tussen de grootste waarde xM en de kleinste xM van een gegevensset:
Bereik = xM - XM
Variantie
Meet hoe ver de gemiddelde waardegegevens zijn. Hiervoor wordt een gemiddelde gemaakt, maar met de verschillen tussen elke waarde xJe en het gemiddelde, kwadratische om te voorkomen dat ze elkaar annuleren. Het wordt meestal aangeduid met de Griekse letter σ vierkante, of met s2:
^2N) Standaardafwijking
Standaardafwijking
De variantie heeft niet dezelfde eenheden als de gegevens, dus de standaardafwijking wordt gedefinieerd als de vierkantswortel van de variantie en wordt aangeduid als σ of s:
^2N) Frequentieverdeling
Frequentieverdeling
In plaats van rekening te houden met elke gegevens afzonderlijk, heeft het de voorkeur om ze in reeksen te groeperen, wat het werk vergemakkelijkt, vooral als er veel waarden zijn. Bijvoorbeeld, wanneer ze met de kinderen van een school werken, kunnen ze worden gegroepeerd in leeftijdsbereiken: van 0 tot 6 jaar, van 6 tot 12 jaar en van 12 tot 18 jaar.
Grafieken
Ze vormen een uitstekende manier om de verdeling van een weergavegegevens te waarderen en alle informatie in de tabellen en foto's te bevatten, maar veel betaalbaarder.
Er is een grote verscheidenheid van hen: met balken, lineair, cirkelvormig, stengel en blad, histogrammen, frequentie polygonen en pictogrammen. Voorbeelden van statistische grafieken worden gepresenteerd in figuur 3.
Thema's van belangstelling
Statistiektakken.
Statistische variabelen.
Bevolking en steekproef.
Inferentiële statistieken.
Referenties
- Faraldo, p. Statistieken en onderzoeksmethodologie. Hersteld van: eio.USC.is.
- Fernández, s. 2002. Beschrijvende statistieken. 2e. Editie. ESIC -redactie. Hersteld van: Google Books.
- Statistiekengeschiedenis. Hersteld van: Eumed.netto.
- Ibañez, P. 2010. Wiskunde II. Competentiebenadering. Cengage leren.
- Monroy, s. 2008. Beschrijvende statistieken. 1e. Editie. National Polytechnic Institute of Mexico.
- Universe -formules. Beschrijvende statistieken. Hersteld van: UniversOFormulas.com.
- « Variatiecoëfficiënt waarvoor het is, berekening, voorbeelden, oefeningen
- Inferentiële statistiekengeschiedenis, kenmerken, waarvoor is het voor voorbeelden »