

Empirische regel hoe het toe te passen, waarvoor is het opgelost, oefeningen

- 1441
- 246
- Alton D'Amore
A Empirische regel Het is het resultaat van de praktische ervaring en de observatie van het echte leven. U kunt bijvoorbeeld weten dat vogelsoorten op bepaalde plaatsen in elke tijd van het jaar kunnen worden waargenomen en dat observatie kan worden vastgesteld een "regel" die de levenscycli van deze vogels beschrijft.
In statistieken verwijst de empirische regel naar de vorm van de groepering van waarnemingen rond een centrale waarde, gemiddeld of gemiddeld, in standaardafwijkingseenheden.
Stel dat je een groep mensen hebt met een gemiddelde hoogte van 1.62 meter en een standaardafwijking van 0.25 meter, dan zou de empirische regel het mogelijk maken om bijvoorbeeld te definiëren hoeveel mensen in een interval van het gemiddelde min of meer een standaardafwijking zouden zijn?
Volgens de regel is 68% van de gegevens min of meer een standaardafwijking van het gemiddelde, dat wil zeggen 68% van de groepsmensen zal een hoogte hebben tussen 1.37 (1.62-0.25) en 1.87 (1.62+0.25) METER.
[TOC]
Waar komt de empirische regel vandaan??
De empirische regel is een generalisatie van de stelling van Tchebyshev en de normale verdeling.
Tchebyshev stelling
De stelling van Tchebyshev zegt dat: voor een waarde van k> 1, de kans dat een willekeurige variabele tot de gemiddelde minder k maal is, de standaardafwijking, en de gemiddelde meer k -tijden, de standaardafwijking is groter dan of gelijk aan (1-1 /K2)).
Het voordeel van deze stelling is dat het van toepassing is op discrete of continue willekeurige variabelen met een waarschijnlijkheidsverdeling, maar de daaruit gedefinieerde regel is niet altijd erg nauwkeurig, omdat het afhangt van de symmetrie van de verdeling. Hoe meer asymmetrisch de verdeling van de willekeurige variabele, minder aangepast aan de regel zal het gedrag zijn.
De empirische regel gedefinieerd uit deze stelling is:
Als k = √2 wordt gezegd dat 50% van de gegevens in het interval zijn: [µ - √2 s, µ + √2 s]
Als k = 2 wordt gezegd dat 75% van de gegevens in het interval zijn: [µ - 2 s, µ + 2 s]
Als k = 3 wordt gezegd dat 89% van de gegevens in het interval zijn: [µ - 3 s, µ + 3 s]
Normale verdeling
De normale verdeling, of Gauss Bell, maakt het mogelijk om de empirische regel vast te stellen of regel 68 - 95 - 99.7.
Kan u van dienst zijn: proportieDe regel is gebaseerd op de kansen op het optreden van een willekeurige variabele met intervallen tussen de gemiddelde minder één, twee of drie standaardafwijkingen en het gemiddelde plus één, twee of drie standaardafwijkingen.
De empirische regel definieert de volgende intervallen:
68.27% van de gegevens staat in het interval: [µ - s, µ + s]
95.45% van de gegevens staat in het interval: [µ - 2s, µ + 2s]
99.73% van de gegevens staat in het interval: [µ - 3s, µ + 3s]
In de figuur kun je zien hoe deze intervallen worden gepresenteerd en de relatie daartussen door de breedte van de grafische basis te vergroten.
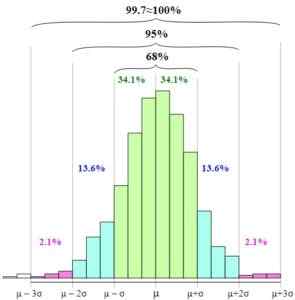 Empirische regel. Melikamp [CC BY-SA 4.0 (https: // creativeCommons.org/)]] De standaardisatie van de willekeurige variabele, dat wil zeggen de expressie van de willekeurige variabele in termen van de standaard of normale variabele, vereenvoudigt het gebruik van de empirische regel, omdat de variabele z gemiddeld gelijk is aan nul- en standaardafwijking gelijk tot een.
Empirische regel. Melikamp [CC BY-SA 4.0 (https: // creativeCommons.org/)]] De standaardisatie van de willekeurige variabele, dat wil zeggen de expressie van de willekeurige variabele in termen van de standaard of normale variabele, vereenvoudigt het gebruik van de empirische regel, omdat de variabele z gemiddeld gelijk is aan nul- en standaardafwijking gelijk tot een.
Daarom definieert de toepassing van de empirische regel op schaal van een standaard normale variabele, Z, de volgende intervallen:
68.27% van de gegevens staat in het interval: [-1, 1]
95.45% van de gegevens staat in het interval: [-2, 2]
99.73% van de gegevens staat in het interval: [-3, 3]
Hoe de empirische regel toe te passen?
Met de empirische regel kunt u berekeningen afkorten bij het werken met een normale verdeling.
Stel dat een groep van 100 universitaire studenten een gemiddelde leeftijd van 23 jaar heeft, met een standaardafwijking van 2 jaar. Welke informatie staat de empirische regel toe?
De toepassing van de empirische regel impliceert het volgen van de stappen:
1- Bouw de regelintervallen
Omdat het gemiddelde 23 is en de standaardafwijking 2 is, zijn de intervallen:
[µ - s, µ + s] = [23 - 2, 23 + 2] = [21, 25]
[µ - 2s, µ + 2s] = [23 - 2 (2), 23 + 2 (2)] = [19, 27]
[µ - 3s, µ + 3s] = [23 - 3 (2), 23 + 3 (2)] = [17, 29]
2- Bereken het aantal studenten in elk interval volgens de percentages
(100)*68.27% = 68 studenten ongeveer
(100)*95.45% = ongeveer 95 studenten
(100)*99.73% = 100 studenten
3- AGES -intervallen worden geassocieerd met de hoeveelheden studenten en geïnterpreteerd
Minstens 68 studenten zijn tussen de 21 en 25 jaar oud.
Kan u van dienst zijn: beschrijvende statistieken: geschiedenis, kenmerken, voorbeelden, conceptenMinstens 95 studenten zijn tussen de 19 en 27 jaar oud.
Vrijwel 100 studenten zijn tussen de 17 en 29 jaar oud.
Waar is de empirische regel voor?
De empirische regel is een snelle en praktische manier om statistische gegevens te analyseren, die steeds betrouwbaarder zijn in de mate dat de verdeling dicht bij symmetrie ligt.
Het nut ervan hangt af van het veld waarin het wordt gebruikt en de vragen die zich voordoen. Het is zeer nuttig om te weten dat het optreden van waarden van drie standaardafwijkingen bijna onwaarschijnlijk is onder of boven het gemiddelde, zelfs voor niet -normale distributievariabelen, ten minste 88.8% van de gevallen bevindt zich in het drie sigma -interval.
In de sociale wetenschappen is een algemeen sluitend resultaat het interval van het gemiddelde min of meer twee sigma (95%), terwijl in de deeltjesfysica een nieuw effect een vijf Sigmas -interval vereist (99.99994%) om als een ontdekking te worden beschouwd.
Opgeloste oefeningen
Konijnen in het reservaat
In een natuurreserve wordt geschat dat er een gemiddelde van 16 is.000 konijnen met een standaardafwijking van 500 konijnen. Als de verdeling van de variabele 'aantal konijnen in de reserve' onbekend is, is het dan mogelijk.000 en 17.000 konijnen?
Het interval kan in deze termen worden gepresenteerd:
15000 = 16000 - 1000 = 16000 - 2 (500) = µ - 2 s
17000 = 16000 + 1000 = 16000 + 2 (500) = µ + 2 s
Daarom: [15000, 17000] = [µ - 2 s, µ + 2 s]
Door de stelling van Tchebyshev toe te passen, is er een kans op minstens 0.75 dat de bevolking van konijnen van het natuurreservaat tussen de 15 ligt.000 en 17.000 konijnen.
Gemiddelden van kinderen uit een land
Het gemiddelde gewicht van één -jarige kinderen wordt normaal verdeeld met een gemiddelde van 10 kilogram en een standaardafwijking van ongeveer 1 kilogram.
a) Schat het percentage van één jaar kinderen in het land met een gemiddeld gewicht tussen 8 en 12 kilogram.
8 = 10 - 2 = 10 - 2 (1) = µ - 2 s
12 = 10 + 2 = 10 + 2 (1) = µ + 2 s
Daarom: [8, 12] = [µ - 2s, µ + 2s]
Het kan u van dienst zijn: Tukey -test: wat is, in het geval van bijvoorbeeld, opgeloste oefeningVolgens de empirische regel kan worden bevestigd dat 68.27% van de kinderen in het land heeft tussen de 8 en 12 kilogram gewicht.
b) Wat is de kans om een kind van één jaar te vinden van 7 kilogram of minder gewicht?
7 = 10 - 3 = 10 - 3 (1) = µ - 3 s
Het is bekend dat 7 kilogram gewicht de waarde µ - 3s vertegenwoordigt, evenals bekend dat 99.73% van de kinderen is tussen 7 en 13 kilogram gewicht. Dat laat slechts 0 achter.27% van de totale kinderen voor de uitersten. De helft van hen, 0.135%, heeft 7 kilogram gewicht of minder en de andere helft, 0.135%, heeft 11 kilogram gewicht of meer.
Dus kan worden geconcludeerd dat er een kans is op 0.00135 dat een kind 7 kilogram gewicht of minder heeft.
c) Als de bevolking van het land 50 miljoen inwoners en de kinderen van 1 jaar bereikt?
9 = 10 - 1 = µ - s
11 = 10 + 1 = µ + S
Daarom: [9, 11] = [µ - s, µ + s]
Volgens de empirische regel, 68.27% van één -jarige kinderen zijn in het interval [µ -s, µ + s]
In het land zijn er 500.000 kinderen van één jaar (1% van 50 miljoen), dus 341350 kinderen (68.27% van 500000) hebben tussen 9 en 11 kilogram gewicht.
Referenties
- ABRAIRA, V. (2002). Standaardafwijking en standaardfout. Semergen magazine. Web hersteld.Archief.borg.
- Freund, r.; Wilson, W.; Mohr, D. (2010). Statistische methoden. Derde Ed. Academische Press-Elsevier Inc.
- Alicante Server (2017). Empirische regel (statistische termen). Woordenlijst hersteld.Server-alive.com.
- Lind, D.; Marchal, W.; Wathen, s. (2012). Statistieken van toepassing op zakelijke en economie. Tiende Ed. McGraw-Hill/Inter-American uit Mexico S. NAAR.
- Salinas, h. (2010). Statistieken en waarschijnlijkheden. Hersteld van UDA.Klet.
- Sokal, r.; Rohlf, f. (2009). Inleiding tot biostatistiek. Tweede Ed. Dover Publications, Inc.
- Spiegel, m. (1976). Waarschijnlijkheid en statistieken. Schaum -serie. McGraw-Hill/Inter-American uit Mexico S. NAAR.
- Spiegel, m.; Stephens, L. (2008). Statistieken. Vierde Ed. McGraw-Hill/Inter-American uit Mexico S. NAAR.
- Stat119 Review (2019). Empirisch oplossende regelvragen. Opgehaald van Stat119Review.com.
- (2019). 68-95-99.7 regel. Opgehaald van.Wikipedia.borg.
- « Homocediciteit wat is, belang en voorbeelden
- Willekeurig experimentconcept, voorbeeldruimte, voorbeelden »