

Relationele databasemodelelementen, hoe het te doen, voorbeeld
- 2762
- 704
- Dewey Powlowski
Hij Relationeel model van databases Het is een methode om gegevens te structureren met behulp van relaties, via roostervormige structuren, die bestaan uit kolommen en rijen. Het is het conceptuele principe van relationele databases. Werd voorgesteld door Edgar F. Codd in 1969.
Sindsdien is het het dominante databasemodel geworden voor commerciële applicaties, in vergelijking met andere databasemodellen, zoals hiërarchisch, netwerk en object.
Bron: Pixabay.com Codd had geen idee van het uiterst vitale en invloedrijke dat zijn werk zou zijn als een platform voor relationele databases. De meeste mensen zijn zeer bekend met de fysieke uitdrukking van een relatie in een database: de tabel.
Het relationele model wordt gedefinieerd als de database waarmee zijn gegevenselementen kunnen groeperen in een of meer onafhankelijke tabellen, die aan elkaar kunnen worden gerelateerd door gemeenschappelijke velden te gebruiken voor elke gerelateerde tabel.
[TOC]
Database management
Een database is vergelijkbaar met een spreadsheet. Door de relaties die tussen de tabellen kunnen worden aangemaakt, kunnen een relationele database echter een grote hoeveelheid gegevens opslaan, die effectief kunnen worden hersteld.
Het doel van het relationele model is om een declaratieve methode te bieden om de gegevens en overleg te specificeren: gebruikers geven direct aan welke informatie de database bevat en welke informatie u ervan wilt.
Aan de andere kant laten ze de software van het databasebeheersysteem verantwoordelijk zijn voor het beschrijven van gegevensstructuren voor opslag- en herstelprocedure om te reageren.
De meeste relationele databases gebruiken de SQL -taal voor de consultatie en definitie van de gegevens. Er zijn momenteel veel relationele databasebeheersystemen of RDBMS (Relational Data Base Management System), zoals Oracle, IBM DB2 en Microsoft SQL Server.
Kenmerken en elementen
- Alle gegevens worden conceptueel weergegeven als een geordende beschikking van gegevens in rijen en kolommen, genaamd Relatie of Tabel.
- Elke tafel moet een koptekst en een lichaam hebben. De kop is gewoon de kolomlijst. Het lichaam is de set gegevens die de tabel vult, georganiseerd in rijen.
- Alle waarden zijn beklimmen. Dat wil zeggen, in een bepaalde positie van rij/kolom in de tabel is er slechts één unieke waarde.
-Items
De volgende figuur toont een tabel met de namen van de basiselementen, die een volledige structuur vormen.
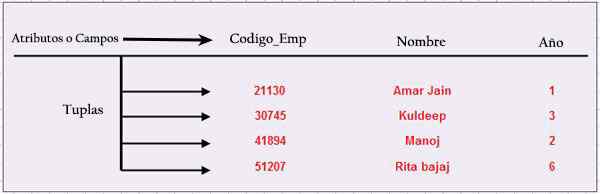
Tupla
Elke rij gegevens is een tupla, ook bekend als registratie. Elke rij is een N-TUPLA, maar de "N-" is over het algemeen uitgesloten.
Kolom
Elke kolom van een tupla wordt attribuut of veld genoemd. De kolom vertegenwoordigt de set waarden die een specifiek kenmerk kan hebben.
Aanwijzing
Elke rij heeft een of meer kolommen die de tabel worden genoemd. Deze gecombineerde waarde is uniek voor alle rijen van een tabel. Door deze sleutel wordt elke tuplla op een onduidelijke manier geïdentificeerd. Dat wil zeggen, de sleutel kan niet worden gedupliceerd. Het wordt primaire sleutel genoemd.
Aan de andere kant is een externe of secundaire sleutel het veld van een tabel die verwijst naar de primaire sleutel van een andere tabel. Het wordt gebruikt om te verwijzen naar de primaire tabel.
-Integriteitsregels
Bij het ontwerpen van het relationele model worden enkele voorwaarden die moeten worden voldaan in de database, die integriteitsregels worden genoemd, gedefinieerd.
Kan u van dienst zijn: macrocomputers: geschiedenis, kenmerken, gebruik, voorbeeldenBelangrijke integriteit
De primaire sleutel moet uniek zijn voor alle tupels en kan de nulwaarde niet hebben (null). Anders kunt u de rij niet uitsluitend identificeren.
Voor een sleutel die uit verschillende kolommen is samengesteld, kan geen van die kolommen nul bevatten.
Referentiële integriteit
Elke waarde van een externe sleutel moet samenvallen met een waarde van de primaire sleutel in de genoemde of primaire tabel.
In de secundaire tabel kan slechts één rij worden ingevoegd met een externe sleutel als die waarde in een primaire tabel bestaat.
Als de waarde van de sleutelwisselingen in de primaire tabel, voor het bijwerken of elimineren van de rij, dan moeten alle rijen in de secundaire tabellen met deze externe sleutel worden bijgewerkt of dienovereenkomstig worden geëlimineerd.
Hoe u een relationeel model kunt maken?
-Data verzamelen
De benodigde gegevens om ze in de database op te slaan, moeten worden verzameld. Deze gegevens zijn verdeeld in verschillende tabellen.
Voor elke kolom moet een geschikt gegevenstype worden gekozen. Bijvoorbeeld: hele getallen, drijvende puntnummers, tekst, datum, enz.
-Definieer primaire sleutels
Voor elke tabel moet u een kolom (of enkele kolommen) kiezen als een primaire sleutel, die elke rij van de tabel uniek zal identificeren. De primaire sleutel wordt ook gebruikt om te verwijzen naar andere tabellen.
-Creëer relaties tussen tafels
Een database bestaande uit onafhankelijke en niet -gerelateerde tabellen heeft weinig doel.
Het meest cruciale aspect in het ontwerp van een relationele database is het identificeren van de relaties tussen de tabellen. De soorten relatie zijn:
Een te veel
In een "klassen" -database kan een leraar les geven in nul of meer klassen, terwijl een les wordt gegeven door een enkele leraar. Dit type relatie staat bekend als één voor velen.
Deze relatie kan niet in één tabel worden weergegeven. In de "klassenlijst" -database kunt u een tabel hebben genaamd leraren, die informatie over leraren opslaat.
Om de lessen van elke leraar op te slaan, kunnen extra kolommen worden gemaakt, maar een probleem zou worden geconfronteerd: hoeveel kolommen creëren.
Aan de andere kant, als u een tabel met de naam klassen hebt, slaat deze informatie op over een klasse, kan extra kolommen worden gemaakt om informatie over de leraar op te slaan.
Aangezien een leraar in veel klassen echter kan lesgeven, zouden zijn gegevens in veel rangen worden verdubbeld in de klassentabel.
Ontwerp twee tafels
Daarom moeten twee tabellen worden ontworpen: een klassentabel om informatie op te slaan over klassen, met_id -klasse als de belangrijkste sleutel, en een mastertabel om informatie over leraren op te slaan, met leraar_id als de belangrijkste sleutel.
Vervolgens kunt u de relatie maken om de primaire sleutel van de mastertabel (master_id) in de klassentabel op te slaan, zoals hieronder wordt geïllustreerd.
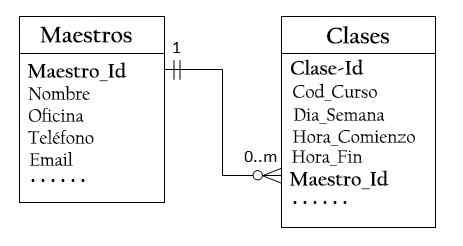
De kolom Master_ID in de klassentabel staat bekend als externe of secundaire sleutel.
Voor elke master_id -waarde in de mastertabel kunnen er nul of meer rijen in de klassentabel zijn. Voor elke klasse_id -waarde in de klassentabel is er slechts één rij in de mastertabel.
Veel te veel
In een "productverkoop" -database kan de bestelling van een klant verschillende producten bevatten en kan een product in verschillende bestellingen verschijnen. Dit type relatie is voor velen bekend.
Het kan u van dienst zijn: ICT (informatie- en communicatietechnologieën)U kunt de "productverkoop" -database starten met twee tabellen: producten en bestellingen. De productentabel bevat informatie over de producten, met product als een primaire sleutel.
Aan de andere kant bevatten de bestellingen klantbestellingen, met aanvragen als primaire code.
U kunt de gevraagde producten niet opslaan in de geordende tabel, omdat het niet bekend is hoeveel kolommen voor de producten reserveren. Om dezelfde reden kunnen bestellingen niet in de tabelproducten worden opgeslagen.
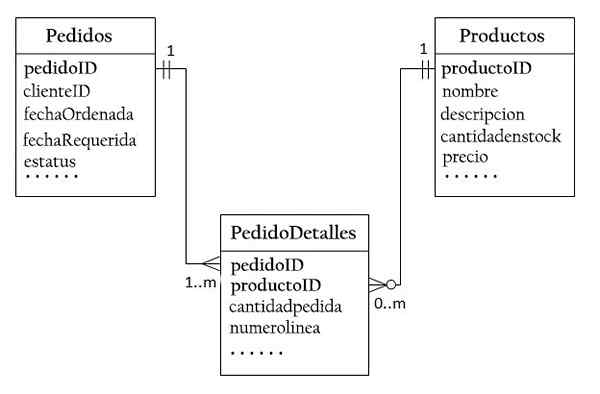
Om een relatie toe te laten velen voor velen, is het noodzakelijk om een derde tabel te maken, bekend als de vakbondstabel (verzoeken), waarbij elke rij een element van een bepaalde volgorde vertegenwoordigt.
Voor de aanvraagtabel bestaat de primaire sleutel uit twee kolommen: bestelling en product, waarbij elke rij elke rij wordt geïdentificeerd.
De gevraagde en productkolommen in het verzoek om de methoden worden gebruikt om naar de bestellingen en producten te verwijzen. Daarom zijn het ook externe sleutels tot het verzoek om het verzoek.
Een voor een
In de database "Productenverkoop" kan een product optionele informatie hebben, als een aanvullende beschrijving en de afbeelding ervan. Houd het in de producten zou veel lege ruimtes genereren.
Daarom kunt u een andere tabel maken (excTS -product) om optionele gegevens op te slaan. Er wordt alleen een record voor producten met optionele gegevens gemaakt.
De twee tafels, producten en product hebben een één -tot -één relatie. Voor elke rij in de producttabel is er een maximale rij in de producttabillen. Hetzelfde product moet worden gebruikt als de belangrijkste sleutel voor beide tabellen.
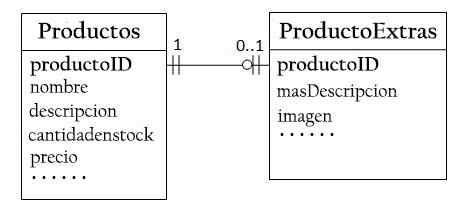
Voordelen
Structurele onafhankelijkheid
In het relationele databasemodel hebben wijzigingen in de databasestructuur geen invloed op de toegang tot gegevens.
Wanneer het mogelijk is om wijzigingen aan te brengen in de structuur van de database zonder het vermogen van de DBM's om toegang te krijgen tot de gegevens, kan worden gezegd dat structurele onafhankelijkheid is bereikt.
Conceptuele eenvoud
Het relationele databasemodel is op conceptueel niveau nog eenvoudiger dan het hiërarchische model of het databasetwerk.
Aangezien het relationele databasemodel de ontwerper vrijgeeft van de details van de fysieke opslag van de gegevens, kunnen de ontwerpers zich concentreren op de logische weergave van de database.
Gemak van ontwerp, implementatie, onderhoud en gebruik
Het relationele databasemodel bereikt zowel de onafhankelijkheid van de gegevens als de onafhankelijkheid van de structuur, waardoor het ontwerp, het onderhoud, de administratie en het gebruik van de database veel eenvoudiger zijn dan de andere modellen.
Ad-hoc consultatiecapaciteit
De aanwezigheid van een zeer krachtige, flexibele en gemakkelijk -voor -gebruiksoverlegcapaciteit is een van de belangrijkste redenen voor de enorme populariteit van het relationele basismodel van de database.
De consultatietaal van het relationele databasemodel, gestructureerde consultatietaal of SQL, maakt ad-hocquery's uit. SQL is een taal van de vierde generatie (4GL).
Met een 4GL kan de gebruiker opgeven wat er moet worden gedaan, zonder aan te geven hoe het moet worden gedaan. Met SQL kunnen gebruikers dus opgeven welke informatie ze willen en de details over hoe de informatie naar de database kan krijgen.
Nadelen
Hardwarekosten
Het relationele databasemodel verbergt de complexiteit van de implementatie ervan en de details van de fysieke opslag van de gebruikersgegevens.
Kan u van dienst zijn: wat zijn G -codes? (Met voorbeeld)Om dit te doen, hebben relationele databasesystemen computers nodig met krachtigere hardware en opslag.
Daarom heeft RDBMS krachtige machines nodig om zonder problemen te werken. Omdat de verwerkingskracht van moderne computers echter in een exponentieel tempo toeneemt, is de behoefte aan meer verwerkingskracht in het huidige scenario niet langer een zeer groot probleem.
Ontwerpgemak kan leiden tot slecht ontwerp
De relationele database is eenvoudig te ontwerpen en te gebruiken. Gebruikers hoeven niet de complexe details van de fysieke opslag van de gegevens te weten. Ze hoeven niet te weten hoe gegevens echt worden opgeslagen om toegang te krijgen.
Dit ontwerp en gebruik gemak kunnen leiden tot de ontwikkeling en implementatie van zeer slecht ontworpen databasebeheersystemen. Aangezien de database efficiënt is, zullen deze ontwerpinefficiënties niet aan het licht komen wanneer de database is ontworpen en wanneer er slechts een kleine hoeveelheid gegevens is.
Naarmate de database groeit, zullen de slecht ontworpen databases het systeem vertragen en een degradatie van gegevensprestaties en corruptie veroorzaken.
Fenomeen van "Information Islands"
Zoals eerder gezegd, zijn relationele databasesystemen eenvoudig te implementeren en te gebruiken. Dit zal een situatie creëren waarin te veel mensen of afdelingen hun eigen databases en applicaties zullen creëren.
Deze informatie -eilanden voorkomen de integratie van informatie, wat essentieel is voor de vloeiende en efficiënte werking van de organisatie.
Deze individuele databases zullen ook problemen veroorzaken zoals gegevensconsistentie, gegevensduplicatie, gegevensredundantie, enz.
Voorbeeld
Stel dat een database bestaat uit de bijvragingstabellen, stukken en verzendingen. De structuur van de tabellen en enkele voorbeeldrecords worden hieronder weergegeven:
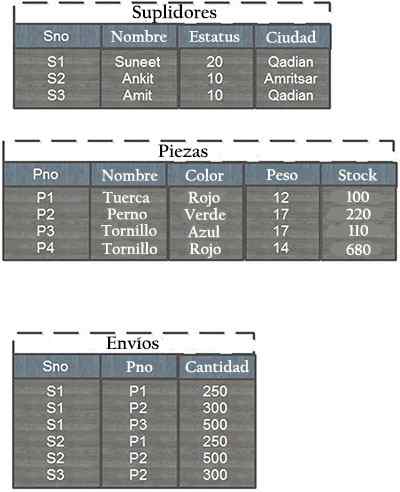
Elke rij in de toevoertabel wordt geïdentificeerd door een uniek leveranciersnummer (SNO), waarbij elke rij van de tabel uniek wordt geïdentificeerd. Evenzo heeft elk stuk een uniek onderdeelnummer (PNO).
Bovendien kan er niet meer dan één verzending zijn voor een bepaalde leverancier / stukcombinatie in de verzendtabel, omdat deze combinatie de primaire verzendtoets is, die dient als een vakbondstabel, omdat velen voor velen een relatie zijn.
De relatie tussen de tabellen en zendingen wordt gegeven door het PNO -veld (stuknummer) gemeen te hebben en de relatie tussen leveranciers en zendingen komt voort uit gemeenschappelijk het SNO -veld (leveranciersnummer).
Het analyseren van de verzendtabel kan worden verkregen als informatie die in totaal 500 noten van de Suneet en Ankit -leveranciers wordt verzonden, elk 250.
Evenzo werden 1 verzonden.100 bouten in totaal van drie verschillende leveranciers. 500 blauwe schroeven werden verzonden van de Suneet Leverancier. Er zijn geen rode schroefzendingen.
Referenties
- Wikipedia, The Free Encyclopedia (2019). Relationeel model. Genomen van: in.Wikipedia.borg.
- Ravepedia (2019). Relationeel model. Genomen uit: Ravepedia.com.
- Diesh Thakur (2019). Relationeel model. Ecomputer Notes. Uitgevoerd uit: Ecomputernotes.com.
- Geeks voor geeks (2019). Relationeel model. Genomen uit: geeksforgeeks.borg.
- Nanyang Technological University (2019). Een snelle tutorial over relationele databaseontwerp. Genomen uit: NTU.Edu.SG.
- Adrienne Watt (2019). Hoofdstuk 7 Het relatie -datamodel. BC Open schoolboeken. Genomen uit: OpenTextbc.AC.
- TOPPR (2019). Relationele databases en schema's. Genomen van: toppr.com.
- « Operations Research What Is It voor, modellen, applicaties
- Vanadio geschiedenis, eigenschappen, structuur, gebruik »