

Hypergeometrische distributieformules, vergelijkingen, model

- 1784
- 514
- Aaron Okuneva
De hypergeometrische verdeling Het is een discrete statistische functie, toereikend om de waarschijnlijkheid te berekenen in willekeurige experimenten met twee mogelijke resultaten. De voorwaarde die nodig is om het toe te passen is dat het kleine populaties zijn, waarbij de extracties niet worden vervangen en de waarschijnlijkheden niet constant zijn.
Daarom, wanneer een element van de populatie wordt gekozen om het resultaat (waar of onwaar) van een bepaald kenmerk te kennen, kan datzelfde element niet opnieuw worden gekozen.
Figuur 1. In een populatie van dergelijke schroeven zijn er zeker defecte exemplaren. Bron: Pixabay. Zeker, het volgende gekozen element is dus waarschijnlijker om een echt resultaat te behalen, als het vorige element een negatief resultaat had. Dit betekent dat de kans varieert, voor zover elementen van het monster worden geëxtraheerd.
De belangrijkste toepassingen van hypergeometrische verdeling zijn: kwaliteitscontrole in processen met weinig populatie en de berekening van kansen in willekeurige games.
Wat betreft de wiskundige functie die hypergeometrische verdeling definieert, dit bestaat uit drie parameters, die zijn:
- Populatie -elementen nummer (n)
- Steekproefgrootte (m)
- Aantal evenementen in de complete bevolking met een gunstig (of ongunstig) resultaat van het onderzochte kenmerk (n).
[TOC]
Formules en vergelijkingen
De hypergeometrische verdelingsformule geeft waarschijnlijkheid P over wat X gunstige gevallen van een bepaald kenmerk treden op. De manier om het wiskundig te schrijven, afhankelijk van combinatorische nummers is:
=\frac\binomnx\binomN-nm-x\binomNm)
In de vorige uitdrukking N, N En M Het zijn parameters en X de variabele zelf.
-Totale bevolking is N.
-Aantal positieve resultaten van een bepaald binair kenmerk met betrekking tot de totale populatie is N.
-Aantal elementen van het monster is M.
In dit geval, X Het is een willekeurige variabele die waarde neemt X En P (x) duidt op de kans op het optreden van X Gunstige gevallen van het onderzochte kenmerk.
Belangrijke statistische variabelen
Andere statistische variabelen voor hypergeometrische verdeling zijn:
- Half μ = m*n/n
- Variantie σ^2 = m*(n/n)*(1-n/n)*(n-m)/(n-1)
- Typische afwijking σ dat is de vierkantswortel van de variantie.
Model en eigenschappen
Om het hypergeometrische distributiemodel te bereiken, is het gebaseerd op de kans op verkrijgen X gunstige gevallen in een size monster M. Deze steekproef bevat elementen die voldoen aan het onderzochte eigendom en elementen die dat niet doen.
Laten we dat onthouden N vertegenwoordigt het aantal gunstige gevallen in de totale bevolking van N items. Dan zou de waarschijnlijkheid als volgt worden berekend:
Kan u van dienst zijn: Vector Space: Base en Dimension, Axioms, PropertiesP (x) = (# manieren om x# op mislukte manieren te verkrijgen)/(# Totaal aantal manieren van selecteren)
Door het bovenstaande te uitdrukken in de vorm van combinatorische getallen, wordt het volgende waarschijnlijkheidsdistributiemodel bereikt:
Belangrijkste eigenschappen van hypergeometrische verdeling
Zijn het volgende:
- De steekproef moet altijd klein zijn, hoewel de populatie groot is.
- De elementen van de steekproef worden uit één geëxtraheerd, zonder ze opnieuw in de bevolking op te nemen.
- Het te bestuderen eigenschap is binair, dat wil zeggen dat het slechts twee waarden kan kosten: 1 of 0, O goed WAAR of nep.
In elke stap -extractiestap verandert de waarschijnlijkheid afhankelijk van de vorige resultaten.
Benadering door binomiale verdeling
Een andere eigenschap van hypergeometrische verdeling is dat het kan worden benaderd door binomiale verdeling, aangeduid als Bi, Zolang de bevolking N Wees groot en ten minste 10 keer groter dan het monster M. In dit geval zou het zo zijn:
P (n, n, m; x) = bi (m, n/n, x)
Zolang n groot is en n> 10m
Voorbeelden
voorbeeld 1
Stel dat een machine die schroeven produceert en data -gegevens produceert, aangeeft dat 1% met defecten komt. Vervolgens zal het aantal defecten in een doos met n = 500 schroeven zijn:
N = 500 * 1/100 = 5
Waarschijnlijkheden door hypergeometrische verdeling
Stel dat we uit die doos (dat wil zeggen van die populatie) een steekproef van M = 60 schroeven nemen.
De kans dat geen schroef (x = 0) van het monsterbladeren defect is 52,63%. Dit resultaat wordt bereikt bij het gebruik van de hypergeometrische distributiefunctie:
P (500, 5, 60; 0) = 0,5263
De kans dat x = 3 monsterschroeven defect verlaten is: P (500, 5, 60; 3) = 0,0129.
Aan de andere kant is de kans dat x = 4 schroeven van de jaren zestig van het monsterverlof defect is: P (500, 5, 60; 4) = 0,0008.
Ten slotte is de kans dat x = 5 schroeven in dat monster met defect komen: P (500, 5, 60; 5) = 0.
Maar als u de kans wilt weten dat er in dat monster meer dan 3 defecte schroeven zijn, moet de opgebouwde waarschijnlijkheid worden verkregen, wat toevoegt:
P (3)+P (4)+P (5) = 0,0129+0,0008+0 = 0,0137.
Dit voorbeeld wordt geïllustreerd in figuur 2, verkregen door het gebruik van Geogebra Breed gebruik gratis software op scholen, instituten en universiteiten.
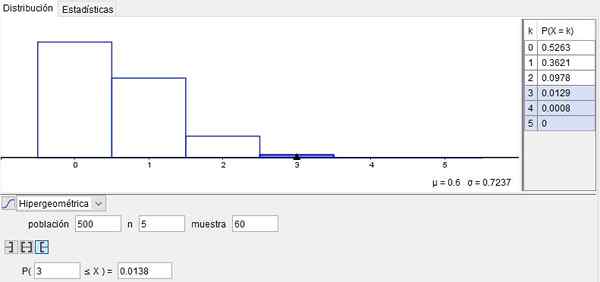 Figuur 2. Voorbeeld van hypergeometrische verdeling. Bereid door f. Zapata met Geogebra.
Figuur 2. Voorbeeld van hypergeometrische verdeling. Bereid door f. Zapata met Geogebra. Voorbeeld 2
Een Spaans dekdek heeft 40 kaarten, waarvan er 10 goud hebben en de resterende 30 hebben het niet. Stel dat 7 kaarten uit dat dek worden gehaald, die niet terugkeren naar het dek.
Kan u van dienst zijn: Centrale symmetrie: eigenschappen, voorbeelden en oefeningenAls X het aantal goud is dat aanwezig is in de 7 geëxtraheerde kaarten, dan wordt de waarschijnlijkheid die x oros zijn in een extractie van 7 kaarten gegeven door de hypergeometrische verdeling P (40,10,7; x).
Laten we dit eens kijken: om de kans te berekenen van 4 goud in een extractie van 7 kaarten, gebruiken we de hypergeometrische distributieformule met de volgende waarden:
=\frac\binom104\binom40-107-4\binom407)
En het resultaat is: 4,57% waarschijnlijkheid.
Maar als u de kans wilt weten om meer dan 4 kaarten te verkrijgen, moeten we toevoegen:
P (4)+P (5)+P (6)+P (7) = 5,20%
Opgeloste oefeningen
De volgende reeks oefeningen is bedoeld om de concepten die in dit artikel zijn gepresenteerd te illustreren en te assimileren. Het is belangrijk dat de lezer ze zelf probeert op te lossen, voordat hij naar de oplossing kijkt.
Oefening 1
Een profylactische fabriek heeft ontdekt dat van elke 1000 condooms die door een bepaalde machine worden geproduceerd, 5 defect zijn. Om kwaliteitscontrole uit te voeren, worden 100 condooms willekeurig genomen en wordt de partij afgewezen als er minstens een of meer defect is. Antwoord:
a) Welke mogelijkheid moet een 100 lot weggooien zijn?
b) Is dit kwaliteitscontrolecriterium efficiënt?
Oplossing
In dit geval verschijnen er zeer grote combinatorische nummers. De berekening is moeilijk, tenzij er een adequaat computerpakket beschikbaar is.
Maar omdat het een grote populatie is en de steekproef tien keer minder is dan de totale populatie, kunt u de benadering van hypergeometrische verdeling gebruiken als gevolg van binomiale verdeling:
P (1000,5,100; X) = BI (100, 5/1000, X) = BI (100, 0.005, x) = c (100, x)*0.005^x (1-0.005)^(100-X)
In de vorige uitdrukking C (100, x) Het is een combinatorisch nummer. Dan zal de kans op haya meer dan één defect als volgt worden berekend:
P (x> = 1) = 1 - bi (0) = 1-.6058 = 0.3942
Het is een uitstekende aanpak, in vergelijking met de verkregen waarde bij het toepassen van de hypergeometrische verdeling: 0.4102
Men kan gezegd dat, 40% waarschijnlijkheid, veel van 100 profylactics moeten worden weggegooid, wat niet erg efficiënt is.
Maar zijn iets minder veeleisend in het kwaliteitscontroleproces en weggooien.
Oefening 2
Een plastic taco -machine werkt zodanig dat van elke 10 stukken, één is vervormd. In een monster van 5 stuk moet de mogelijkheid één stuk defect zijn.
Oplossing
Bevolking: n = 10
Kan u van dienst zijn: Pythagorische identiteiten: demonstratie, bijvoorbeeld oefeningenNummer n defect voor elke n: n = 1
Steekproefgrootte: M = 5
P (10, 1, 5; 1) = C (1.1)*C (9.4)/c (10.5) = 1*126/252 = 0.5
Daarom is er een kans van 50% dat in een steekproef van 5 een taco misvormd komt.
Oefening 3
In een bijeenkomst van jonge middelbare scholen zijn er 7 dames en 6 heren. Onder de meisjes, 4 studeren geesteswetenschappen en 3 wetenschappen. In de groep jongens bestudeert 1 geesteswetenschappen en 5 wetenschappen. Bereken het volgende:
a) willekeurig kiezen van drie meisjes: wat zijn de kans dat alle geesteswetenschappen bestuderen?.
b) Als drie aanwezigen willekeurig worden gekozen voor de ontmoeting met vrienden: wat zijn drie van hen, ongeacht seks, bestudeer de drie of geesteswetenschappen ook alle drie?.
c) Selecteer nu twee willekeurige vrienden en bel nu X naar de willekeurige variabele "Aantal van degenen die geesteswetenschappen bestuderen". Bepaal van de twee gekozen de gemiddelde of verwachte waarde van X en de variantie σ^2.
Oplossing voor
De bevolking is het totale aantal meisjes: n = 7. Die studie geesteswetenschappen zijn n = 4, van het totaal. De willekeurige steekproef van meisjes zal m = 3 zijn.
In dat geval worden de kans dat de drie geesteswetenschappen zijn gegeven door de hypergeometrische functie:
P (n = 7, n = 4, m = 3, x = 3) = c (4, 3) c (3, 0) / c (7, 3) = 0.1143
Dan is er 11.4% waarschijnlijkheid dat drie willekeurige chica's geesteswetenschappen bestuderen.
Oplossing B
De te gebruiken waarden zijn:
-Bevolking: n = 14
-Hoeveelheid die letters bestudeert, is: n = 6 en de
-Steekproefgrootte: M = 3.
-Aantal vrienden die geesteswetenschappen studeren: x
Volgens dit betekent x = 3 dat de drie studie geesteswetenschappen, maar x = 0 betekent dat niemand geesteswetenschappen bestudeert. De kans dat de drie bestuderen hetzelfde wordt gegeven door de som:
P (14, 6, 3, x = 0) + P (14, 6, 3, x = 3) = 0.0560 + 0.1539 = 0.2099
Vervolgens hebben we een waarschijnlijkheid van 21% dat drie bijeenkomsten die willekeurig worden gekozen, hetzelfde bestuderen.
Oplossing C
Hier hebben we de volgende waarden:
N = 14 totale vriendenpopulatie, n = 6 Totaal aantal in de populatie die geesteswetenschappen bestudeert, de grootte van de steekproef is m = 2.
Hoop is:
E (x) = m * (n/n) = 2 * (6/14) = 0.8572
En de variantie:
σ (x)^2 = m*(n/n)*(1-n/n)*(n-m)/(n-1) = 2*(6/14)*(1-6/14)*(14-2)/(14 -1) =
= 2*(6/14)*(1-6/14)*(14-2)/(14-1) = 2*(3/7)*(1-3/7)*(12) (13) = 0.4521
Referenties
- Discrete waarschijnlijkheidsverdelingen. Hersteld van: tweevoet.gebruik.is
- Statistiek en waarschijnlijkheid. Hypergeometrische verdeling. Opgehaald uit: ProjectodeScartes.borg
- Cdpye-uugr. Hypergeometrische verdeling. Hersteld van: ugr.is
- Geogebra. Klassieke Geogebra, waarschijnlijkheidsberekening. Hersteld van Geogebra.borg
- Gemakkelijke probate. Opgeloste hypergeometrische distributieoefeningen. Hersteld van: Probafacil.com
- Minitab. Hypergeometrische verdeling. Opgehaald uit: ondersteuning.Minitab.com
- Universiteit van Vigo. Belangrijkste discrete distributies. Hersteld van: ANAPG.websites.Uvigo.is
- Bewaarer. Statistieken en combinatorisch. Opgehaald uit: Vitutor.netto
- Weisstein, Eric W. Hypergeometrische verdeling. Hersteld van: Mathworld.Wolfraam.com
- Wikipedia. Hypergeometrische verdeling. Hersteld van: is.Wikipedia.com
- « Willekeurig experimentconcept, voorbeeldruimte, voorbeelden
- Binomiaal distributieconcept, vergelijking, kenmerken, voorbeelden »