

Normale formuleverdeling, kenmerken, bijvoorbeeld oefening
- 3477
- 44
- Dewey Powlowski
De normale verdeling o Gaussiaanse verdeling is de waarschijnlijkheidsverdeling in continue variabele, waarbij de waarschijnlijkheidsdichtheidsfunctie wordt beschreven door een exponentiële functie van kwadratisch en negatief argument, wat resulteert in een afgebroken vorm.
De normale distributienaam komt van het feit dat deze verdeling degene is die wordt toegepast op het grootste aantal situaties waarin een continue willekeurige variabele betrokken is bij een bepaalde groep of populatie.
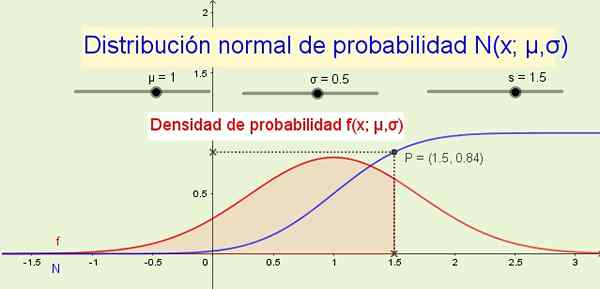
Figuur 1. Normale verdeling N (x; μ, σ) en zijn kansdichtheid F (s; μ, σ). (Eigen uitwerking) Als voorbeelden waar normale verdeling wordt toegepast: de hoogte van mannen of vrouwen, variaties in de mate van een fysieke omvang of in meetbare psychologische of sociologische kenmerken zoals het intellectuele quotiënt of de consumptiegewoonten van een bepaald product.
Aan de andere kant wordt het de Gaussiaanse distributie of Gauss Bell genoemd, omdat het dit Duitse wiskundige genie is dat is gecrediteerd met zijn ontdekking voor het gebruik dat hij gaf voor de beschrijving van de statistische fout van astronomische metingen in 1800.
Er wordt echter beweerd dat deze statistische verdeling eerder werd gepubliceerd door een andere grote wiskundige van Franse afkomst, zoals Abraham de Moivre, in 1733.
[TOC]
Formule
Naar de normale verdelingsfunctie in de continue variabele X, Met parameters μ En σ Het wordt aangeduid door:
N (x; μ, σ)
En expliciet is het als volgt geschreven:
N (x; μ, σ) = ∫-∞X f (s; μ, σ) ds
waar f (u; μ, σ) Het is de waarschijnlijkheidsdichtheidsfunctie:
f (s; μ, σ) = (1/(σ√ (2π)) exp ( - s2/(2σ2))
De constante die de exponentiële functie in de waarschijnlijkheidsdichtheidsfunctie vermenigvuldigt, wordt normalisatieconstante genoemd en is zo gekozen dat:
N (+∞, μ, σ) = 1
De vorige uitdrukking zorgt ervoor dat de kans dat de willekeurige variabele X zijn tussen -∞ en +∞ ofwel 1, dat wil zeggen 100% waarschijnlijkheid.
De parameter μ Het is het rekenkundige gemiddelde van de continue willekeurige variabele x en σ De standaardafwijking of vierkantswortel van de variantie van diezelfde variabele. In het geval dat μ = 0 En σ = 1 U hebt de normale standaard- of normale verdelingsverdeling typisch:
N (x; μ = 0, σ = 1))
Normale verdelingseigenschappen
1- Als een willekeurige statistische variabele een normale waarschijnlijkheidsverdeling volgt f (s; μ, σ), De meeste gegevens zijn gegroepeerd rond de gemiddelde waarde μ En ze zijn om hen heen verspreid, zodat net over de gegevens tussen μ - σ En μ + σ.
Kan u van dienst zijn: absolute frequentie: formule, berekening, verdeling, voorbeeld2- De standaardafwijking σ Het is altijd positief.
3- De vorm van de dichtheidsfunctie F Het lijkt op die van een bel, dus deze functie wordt vaak Gaussiaanse bel of Gaussiaanse functie genoemd.
4- In een Gaussiaanse verdeling valt het gemiddelde, mediaan en mode samen.
5- De verbuigingspunten van de waarschijnlijkheidsdichtheidsfunctie worden precies gevonden in μ - σ En μ + σ.
6- De F-functie is symmetrisch ten opzichte van een as die door de gemiddelde waarde gaat μ En je hebt nul asymptotisch voor x ⟶ +∞ en x ⟶ ⟶ ∞.
7- Een hogere waarde van σ grotere dispersie, ruis of distanties gegevens rond de gemiddelde waarde. Dat wil zeggen tegen meer σ De klokvorm is meer open. In plaats van σ Klein geeft aan dat de dobbelstenen naar het gemiddelde zwommen en de vorm van de bel is meer gesloten of gericht.
8- De distributiefunctie N (x; μ, σ) geeft de kans aan dat de willekeurige variabele kleiner is dan of gelijk is aan X. In figuur 1 (hierboven) bijvoorbeeld de waarschijnlijkheid P die de variabele X is kleiner dan of gelijk aan 1.5 is 84% en komt overeen met het gebied onder de waarschijnlijkheidsdichtheidsfunctie f (x; μ, σ) Van -∞ tot X.
Vertrouwensintervallen
9- Als de gegevens een normale verdeling volgen, dan zijn 68,26% hiervan tussen μ - σ En μ + σ.
10- 95,44% van de gegevens die een normale verdeling volgen, zijn tussen μ - 2σ En μ + 2σ.
11- 99,74% van de gegevens die een normale verdeling volgen, zijn tussen μ - 3σ En μ + 3σ.
12- Als een willekeurige variabele X Volg een verdeling N (x; μ, σ), Dan de variabele
Z = (x - μ) / σ Volg de standaard normale verdeling N (z; 0,1).
De verandering van de variabele X naar de Z Het wordt standaardisatie of typificatie genoemd en is zeer nuttig op het moment van het toepassen van de standaarddistributietabellen op gegevens die een normale niet-standaardverdeling volgen.
Normale distributietoepassingen
Om de normale verdeling toe te passen is het noodzakelijk om de berekening van de integrale van de waarschijnlijkheidsdichtheid te doorlopen, die vanuit analytisch oogpunt niet eenvoudig is en niet altijd beschikbaar is een computerprogramma dat de numerieke berekening mogelijk maakt. Hiertoe worden de standaard- of getypeerde waardentabellen gebruikt, wat niets meer is dan de normale verdeling in het geval μ = 0 en σ = 1.
Kan u van dienst zijn: gecombineerde bewerkingen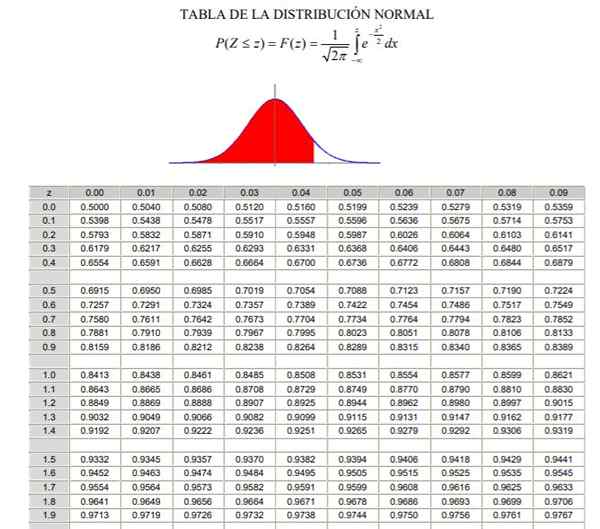 Normale distributietabel getypeerd (deel 1/2)
Normale distributietabel getypeerd (deel 1/2) 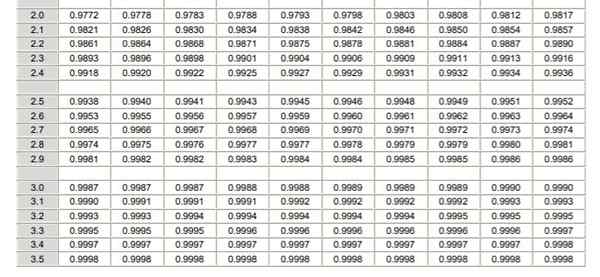 Normale distributietabel getypeerd (deel 2/2)
Normale distributietabel getypeerd (deel 2/2) Opgemerkt moet worden dat deze tabellen geen negatieve waarden bevatten. Met behulp van de symmetrie -eigenschappen van de Gaussiaanse waarschijnlijkheidsdichtheidsfunctie kunnen de overeenkomstige waarden echter worden verkregen. In de opgeloste oefening die hieronder wordt getoond, wordt het gebruik van de tabel in deze gevallen aangegeven.
Voorbeeld
Stel dat u een willekeurige gegevensset X hebt die een normale gemiddelde verdeling van 10 en standaardafwijking 2 volgen. Er wordt gevraagd om de kans te vinden dat:
a) De willekeurige variabele x is kleiner dan of gelijk aan 8.
b) is kleiner dan of gelijk aan 10.
c) Die variabele x is lager dan 12.
d) de kans dat een X -waarde tussen 8 en 12 ligt.
Oplossing:
a) Om de eerste vraag te beantwoorden die u alleen moet berekenen:
N (x; μ, σ)
Met x = 8, μ = 10 En σ = 2. We realiseren ons dat het een integraal is die geen analytische oplossing heeft in elementaire functies, maar de oplossing wordt uitgedrukt volgens de foutfunctie ERF (x).
Aan de andere kant is er de mogelijkheid om de integraal op een numerieke manier op te lossen, wat veel rekenmachines, spreadsheets en computerprogramma's zoals Geogebra doen. De volgende afbeelding toont de numerieke oplossing die overeenkomt met het eerste geval:
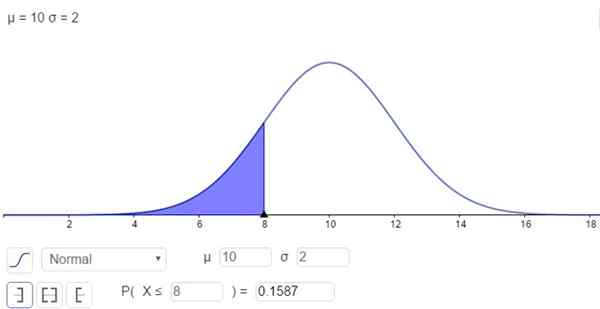 Figuur 2. Waarschijnlijkheidsdichtheid f (x; μ, σ). Het gearceerde gebied vertegenwoordigt P (x ≤ 8). (Eigen uitwerking)
Figuur 2. Waarschijnlijkheidsdichtheid f (x; μ, σ). Het gearceerde gebied vertegenwoordigt P (x ≤ 8). (Eigen uitwerking) En het antwoord is dat de kans dat X lager is dan 8 is:
P (x ≤ 8) = n (x = 8; μ = 10, σ = 2) = 0.1587
b) In dit geval gaat het om het vinden van de kans dat de willekeurige variabele x onder het gemiddelde ligt dat in dit geval 10 waard is. Het antwoord vereist geen berekening, omdat we weten dat de helft van de gegevens lager is dan het gemiddelde en de andere helft boven het gemiddelde. Daarom is het antwoord:
P (x ≤ 10) = n (x = 10; μ = 10, σ = 2) = 0,5
c) Om deze vraag te beantwoorden, moet u berekenen N (x = 12; μ = 10, σ = 2), die kan worden gedaan met een rekenmachine met statistische functies of door software zoals Geogebra:
Kan u van dienst zijn: divisors van 8: wat zijn en gemakkelijke uitleg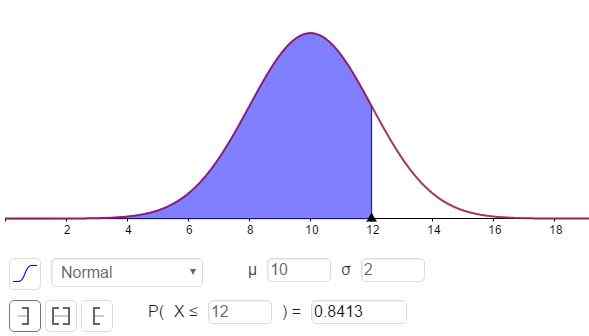 figuur 3. Waarschijnlijkheidsdichtheid f (x; μ, σ). Het gearceerde gebied vertegenwoordigt P (x ≤ 12). (Eigen uitwerking)
figuur 3. Waarschijnlijkheidsdichtheid f (x; μ, σ). Het gearceerde gebied vertegenwoordigt P (x ≤ 12). (Eigen uitwerking) De reactie op deel C is te zien in figuur 3 en is:
P (x ≤ 12) = n (x = 12; μ = 10, σ = 2) = 0.8413.
d) Om de kans te vinden dat de willekeurige variabele x tussen 8 en 12 ligt, kunnen we de resultaten van delen A en C als volgt gebruiken:
P (8 ≤ x ≤ 12) = p (x ≤ 12) - p (x ≤ 8) = 0,8413 - 0,1587 = 0,6826 = 68,26.
Oefening opgelost
De gemiddelde prijs van de aandelen van een bedrijf is $ 25 met een standaardafwijking van $ 4. Bepaal de kans dat:
a) Een actie heeft een kosten minder dan $ 20.
b) dat heeft een kosten hoger dan $ 30.
c) De prijs ligt tussen $ 20 en $ 30.
Gebruik de normale distributietabellen getypeerd om de antwoorden te vinden.
Oplossing:
Om gebruik te maken van de tabellen, is het noodzakelijk om naar de genormaliseerde of getypeerde variabele te gaan:
$ 20 in de gestandaardiseerde variabele is gelijk aan z = ($ 20 - $ 25) / $ 4 = -5/4 = -1,25 en
$ 30 in de gestandaardiseerde variabele is gelijk aan z = ($ 30 - $ 25) / $ 4 = +5/4 = +1.25.
A) $ 20 is gelijk aan -1,25 in de gestandaardiseerde variabele, maar de tabel heeft geen negatieve waarden, dus plaatsen we de +1,25 -waarde die de waarde van 0,8944 toont.
Als deze waarde wordt afgetrokken 0,5 Het resultaat is het gebied tussen 0 en 1,25 dat trouwens identiek is (door symmetrie) naar het gebied tussen -1.25 en 0. Het aftrekkingsresultaat is 0,8944 - 0,5 = 0,3944, wat het gebied is tussen -1.25 en 0.
Maar het gebiedsbelangen van -∞ tot -1,25 die 0,5 -0.3944 = 0.1056 zullen zijn. Daarom wordt geconcludeerd dat de kans dat een actie lager is dan $ 20 10,56% is.
b) $ 30 in de getypeerde variabele z is 1,25. Voor deze waarde in de tabel verschijnt het getal 0.8944 dat overeenkomt met het gebied van -∞ tot +1,25. Het gebied tussen +1.25 y +∞ is (1 - 0.8944) = 0.1056. Met andere woorden, de kans dat een actie meer dan $ 30 kost, is 10,56%.
c) De kans dat een actie een kosten heeft tussen $ 20 en $ 30, wordt als volgt berekend:
100% -10,56% - 10,56% = 78,88%
Referenties
- Statistiek en waarschijnlijkheid. Normale verdeling. Opgehaald uit: ProjectodeScartes.borg
- Geogebra. Klassieke Geogebra, waarschijnlijkheidsberekening. Hersteld van Geogebra.borg
- MathWorks. Gauss -verdeling. Hersteld van: is.MathWorks.com
- Mendenhall, W. 1981. Statistieken voor administratie en economie. 3e. editie. Iberoamerica redactionele groep.
- Stat Trek. Leer jezelf statistieken. Poisson -verdeling. Hersteld van: stattrek.com,
- Triola, m. 2012. Elementaire statistieken. 11e. ED. Pearson Education.
- Universiteit van Vigo. Belangrijkste continue distributies. Hersteld van: ANAPG.websites.Uvigo.is
- Wikipedia. Normale verdeling. Hersteld van: is.Wikipedia.borg
- « XINCA Cultuurgeschiedenis, locatie, kenmerken, wereldbeeld, douane
- Haptes History, Functions, Charactions, Inmunes Antwoorden »