

Gegroepeerde gegevensvoorbeelden en opgeloste oefening

- 2788
- 492
- Cecil Graham
De Gegroepeerde gegevens Zij zijn degenen die hebben ingedeeld in categorieën of klassen, als criteria hun frequentie nemen. Dit wordt gedaan met als doel het beheer van grote hoeveelheden gegevens te vereenvoudigen en hun trends vast te stellen.
Eenmaal georganiseerd in deze klassen voor hun frequenties, vormen de gegevens een Frequentieverdeling, waaruit nutsinformatie wordt geëxtraheerd door zijn kenmerken.
Figuur 1. Met de gegroepeerde gegevens kunt u afbeeldingen bouwen en statistische parameters berekenen die trends beschrijven. Bron: Pixabay. Vervolgens zien we een eenvoudig voorbeeld van gegroepeerde gegevens:
Stel dat de status van 100 vrouwelijke studenten, gekozen uit alle basisfysica -cursussen van een universiteit, wordt gemeten en de volgende resultaten worden verkregen:

De verkregen resultaten werden verdeeld in 5 klassen, die in de linkerkolom verschijnen.
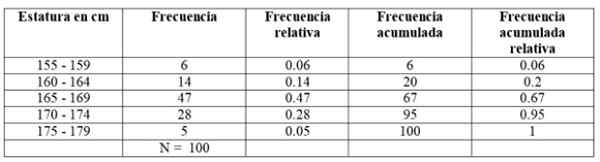
De eerste klas, tussen 155 en 159 cm, heeft 6 studenten, de tweede klas 160 - 164 cm heeft 14 studenten, de derde klas van 165 tot 169 cm is degene met het grootste aantal leden: 47. Volg vervolgens de klas van 170-174 cm met 28 studenten en uiteindelijk die van 175 tot 179 cm met slechts 5.
Het aantal leden van elke klasse is precies de frequentie of Absolute frecuency En door ze allemaal toe te voegen, worden de totale gegevens verkregen, wat in dit voorbeeld 100 is.
[TOC]
Frequentieverdelingskenmerken
Frequentie
Zoals we hebben gezien, is de frequentie het aantal keren dat een feit wordt herhaald. En om de berekeningen van de verdelingseigenschappen, zoals gemiddelde en variantie, te vergemakkelijken, worden de volgende hoeveelheden gedefinieerd:
-Opgebouwde frequentie: Het wordt verkregen door de frequentie van een klasse toe te voegen aan de voorste geaccumuleerde frequentie. De eerste van alle frequenties valt samen met dat van het betreffende interval, en het laatste is het totale aantal gegevens.
-Relatieve frequentie: Het wordt berekend door de absolute frequentie van elke klasse te delen door het totale aantal gegevens. En als u met 100 vermenigvuldigt, heeft u het percentage frequentiepercentage.
Kan u van dienst zijn: vectorfuncties-Verzamelde relatieve frequentie: Het is de som van de relatieve frequenties van elke klasse met de vorige opgebouwde. De laatste van de geaccumuleerde relatieve frequenties moet gelijk zijn aan 1.
Voor ons voorbeeld zijn de frequenties als volgt:
Grenzen
De extreme waarden van elke klasse of interval worden aangeroepen Klassenlimieten. Zoals we kunnen zien, heeft elke klasse een ondergrens en een groter. De eerste klasse van de studie over de beelden heeft bijvoorbeeld een limiet van minder dan 155 cm en een groter dan 159 cm.
Dit voorbeeld heeft limieten die duidelijk zijn gedefinieerd, maar het is mogelijk.
Randen
Hoogte is een continue variabele, dus het kan worden overwogen dat de eerste klasse daadwerkelijk begint in 154.5 cm, omdat door deze waarde af te ronden op het dichtstbijzijnde gehele getal, 155 cm wordt verkregen.
Deze klasse omvat alle waarden tot 159.5 cm, want hieruit zijn de beelden afgerond op 160.0 cm. Een gestalte van 159.7 cm hoort al bij de volgende klas.
De echte klassengrenzen van dit voorbeeld zijn in CM:
- 154.5 - 159.5
- 159.5 - 164.5
- 164.5 - 169.5
- 169.5 - 174.5
- 174.5 - 179.5
Amplitude
De breedte van een klasse wordt verkregen door de grenzen af te trekken. Voor het eerste interval van ons voorbeeld heb je 159.5 - 154.5 cm = 5 cm.
De lezer kan verifiëren dat voor de andere intervallen van het voorbeeld de amplitude ook het gevolg is van 5 cm. Het is echter opmerkelijk dat distributies kunnen worden gebouwd met intervallen van verschillende amplitude.
Het kan u van dienst zijn: regel T: kenmerken, zodat het voorbeelden zijnKlassenmerk
Het is het middelste punt van het interval en wordt verkregen door het gemiddelde tussen de bovengrens en de ondergrens.
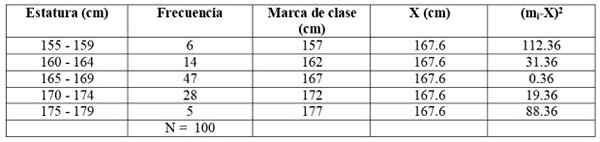
Voor ons voorbeeld is het First Class -merk (155 + 159)/2 = 157 cm. De lezer kan verifiëren dat de resterende klassenmerken zijn: 162, 167, 172 en 177 cm.
Het bepalen van klassenmerken is belangrijk, omdat ze nodig zijn om het rekenkundig gemiddelde en de variantie van de verdeling te vinden.
Maatregelen van centrale neiging en dispersie voor gegroepeerde gegevens
De meest gebruikte centrale tendensmaatregelen zijn gemiddeld, mediaan en mode en beschrijven precies de neiging van de gegevens die rond een bepaalde centrale waarde moeten worden gegroepeerd.
Half
Het is een van de belangrijkste maatregelen voor centrale neiging. In de gegroepeerde gegevens kan het rekenkundig gemiddelde worden berekend met behulp van de formule:

-X is het gemiddelde
-FJe is de frequentie van de klas
-MJe Het is het klassenmerk
-G is het aantal klassen
-n is het totale aantal gegevens
Mediaan
Voor de mediaan moet u het interval identificeren waar de observatie N/2 zich bevindt. In ons voorbeeld is deze observatie nummer 50, omdat er in totaal 100 gegevens zijn. Deze observatie is in het interval 165-169 cm.
Dan moet u interpoleren om de numerieke waarde te vinden die overeenkomt met die observatie, waarvoor de formule wordt gebruikt:
c)
Waar:
-C = intervalbreedte waar de mediaan zich bevindt
-BM = De onderste rand van het interval waartoe de mediaan behoort
-FM = hoeveelheid waarnemingen in het mediane interval
-N/2 = de helft van de totale gegevens
-FBM = Totaal aantal waarnemingen vóór het mediane interval
Mode
Voor mode wordt de modale klasse geïdentificeerd, degene die de meeste observaties bevat, waarvan het klassenmerk bekend is.
Kan je van dienst zijn: zeshoekige piramideVariantie en standaardafwijking
Variantie en standaardafwijking zijn dispersiemaatregelen. Als we de variantie met S aangeven2 En tot de standaardafwijking, die de vierkantswortel is van de variantie als s, voor gegroepeerde gegevens zullen we respectievelijk hebben:
^2n-1)
EN
^2n-1)
Oefening opgelost
Bereken de waarden van: voor de verdeling van de status van universitaire studenten die in het begin worden voorgesteld:
a) Gemiddeld
b) medium
c) mode
D) Variantie en standaardafwijking.
 Figuur 2. Als het gaat om veel waarden, zoals de beelden van een grote groep studenten, heeft het de voorkeur om de gegevens in klassen te groeperen. Bron: Pixabay.
Figuur 2. Als het gaat om veel waarden, zoals de beelden van een grote groep studenten, heeft het de voorkeur om de gegevens in klassen te groeperen. Bron: Pixabay. Oplossing voor
Laten we de volgende tabel bouwen om berekeningen te vergemakkelijken:
 Door de uitdrukking voor de gemiddelde groep die hierboven is gegroepeerd:
Door de uitdrukking voor de gemiddelde groep die hierboven is gegroepeerd:
Waarden vervangen en de som direct uitvoeren:
X = (6 x 157 + 14 x 162 + 47 x 167 + 28 x 172+ 5 x 177) /100 cm =
= 167.6 cm
Oplossing B
Het interval waartoe de mediaan behoort, is 165-169 cm omdat het het meest voorkomende interval is.
Laten we elk van deze waarden in het voorbeeld identificeren, met behulp van tabel 2:
C = 5 cm (zie de sectie Amplitude)
BM = 164.5 cm
FM = 47
N/2 = 100/2 = 50
FBM = 20
Vervangen in de formule:
5\:&space;cm=&space;167.7\:&space;cm) Oplossing C
Oplossing C
Het interval in de meeste observaties is 165-169 cm, waarvan het klassenmerk 167 cm is.
Oplossing D
We breiden de vorige tabel uit door twee extra kolommen toe te voegen:
We passen de formule toe:
En we ontwikkelen de som:
S2 = (6 x 112.36 + 14 x 31.36 + 47 x 0.36 + 28 x 19.36 + 5 x 88.36) / 99 = = 21.35 cm2
Daarom:
S = √21.35 cm2 = 4.6 cm
Referenties
- Berenson, m. 1985. Statistieken voor administratie en economie. Inter -American S.NAAR.
- Canavos, G. 1988. Waarschijnlijkheid en statistieken: toepassingen en methoden. McGraw Hill.
- Devore, J. 2012. Waarschijnlijkheid en statistieken voor engineering en wetenschap. 8e. Editie. Hekelen.
- Levin, r. 1988. Statistieken voor beheerders. 2e. Editie. Prentice Hall.
- Spiegel, m. 2009. Statistieken. Schaum -serie. 4 TA. Editie. McGraw Hill.
- Walpole, r. 2007. Waarschijnlijkheid en statistieken voor engineering en wetenschap. Pearson.
- « U -Test van Mann - Whitney Wat is en wanneer van toepassing, uitvoering, voorbeeld
- Chi-kwadraat (χ²) verdeling, hoe het wordt berekend, voorbeelden »